Blog October 2025¶
LINKS
Kontext and SRPO
Autobiography Stalled
Back Into Video
Python's Odd Behaviour
Trip to Brissie
Gardens & Qwen
Vous Dites Bizarre
Day In the City
About that Queue
Consistent Characters
The Workflow WORKS!
Consistent Characters Two
Kontext and SRPO¶
10.Oct.2025
Having another look at Kontext. Trying to change camera angle, but it turned the figure around instead.


The prompt looked like this:
Rotate the camera 180 degrees showing the woman's back while maintaining the woman's pose.
Getting the camera - and not the figure - to move seems to be a bit tricky. I have yet to achieve that in any image. However, removing hats and changing the time of day is trivial.


The prompt:
Remove the girl's hat to show her chignon updo while maintaining the girl's pose. Turn the background into a nighttime train station scene.
I'll be the first to admit my prompt 'skills' are pretty ordinary. Still. That shows promise.
One of the fun things to do with Kontext is to try different artist styles. No guarantees, of course. I tried Toulouse Lautrec and Claude Monet and got: blah. Certainly not Woman with a Parasol. Oh well.
{kind=link}
AI does reveals about itself as to how it was developed and what it learned, as it portrays the world you are requesting. Yes, it has a viewpoint.


I will take images generated by, say, SRPO (which is a refined Flux model) and then, ask Kontext (also a refined Flux model, but with a different purpose) to ... fix things:
- Brown hair to black
- High detail, photographic precision
- Reduction mammoplasty
And? Well, two out of three isn't bad.
Flux was developed by Black Forest Labs. Yes, that Black Forest. Actually, where I was born, literally: Freiburg Im Breisgau. (they do have a San Francisco office, too). So, the good folks at Black Forest Labs collected data (images) about, well, human proportions, and they would have gone to local sources, perhaps? A beergarden or two? So, my last request to "downsize" was probably met with a quizzical "sorry, can't parse that, mate."
Of course, character consistency went out that window with Kontext. The model is a good one, but sort-of gets lost in the weeds when you start asking for ultra-high detail, whatever. But one thing did get preserved: did you notice the original violinist forgot to "tighten her bow"? So did the black-haired girl. Mistake faithfully preserved. Now, will Kontext understand me if I put that in the prompt? Here's my prompt:

Change the image to ultra-high realistic detail. No male face in this image, only female. Make the woman's breasts small. Render skin tones, hair and face makeup in high detail, with hyper-realistic textures and photographic precision. Change hair color from brown to black. Tighten the violin bow. Tilt the woman's head more to the left.
Nope. No joy. And when I asked it to change the violin to a flute, all I got from Flux was a mirthless laugh.
If I had the patience or the time or the need to get exactly, a specific pose, a precise setup, it could happen, with a bit of patience. There are options. For example, I can take that last image and run it through:
llama-joycation-beta-one-hf-llava:Q4_K_M
... it gives me this:
A photograph of a young woman with long black hair playing a violin indoors. She has fair skin and is wearing an elegant gray dress with a deep V-neckline adorned with silver lace trim, and sheer, bell-shaped sleeves. The dress has a flowing skirt with a slightly gathered waist. She holds the violin delicately in her right hand while drawing the bow with her left hand, her eyes gently closed as she focuses on playing. The background shows a large window with white panes and brown curtains tied back with golden cords. Outside, there is a blurred view of greenery and sunlight filtering through the glass. The overall style is romantic and classical, evoking an old-world charm. The lighting is soft and natural, highlighting her delicate features and the rich color of the violin. The woman appears serene and focused, embodying a sense of grace and musical dedication. The image conveys a peaceful, intimate atmosphere with its warm, gentle colors and elegant composition. This detailed description should provide a clear understanding of the photograph for someone who cannot see it visually.
LLama should write fiction! Now, what I always do is: first, have a read of what llama generated! Because Llama does get it wrong sometimes. In this instance: which hand is doing what, for example. Let's see what Llama is claiming is happening:
She holds the violin delicately in her right hand while drawing the bow with her left hand, her eyes gently closed as she focuses on playing.
"Er, no mate, just the opposite, in fact."
She holds the violin with her chin and at the neck with her left hand and draws the bow with her right.
Lesson learnt: can't trust AI. Still, Llama drew a lovely piccie. Let's fix things:


This photograph depicts a young woman with long black hair playing a violin indoors. She has fair skin and is wearing an elegant Victorian-style (1880s) gray dress with a square neckline adorned with silver lace trim, and sheer, bell-shaped sleeves mostly covering her small bustline. The dress has a flowing skirt with a slightly gathered waist. moim3m3grl She holds the violin delicately in her left hand while drawing the bow with her right hand, her head tilted onto the chin rest of the violin and her eyes gently closed as she focuses on playing. The background shows a large window with white panes and brown curtains tied back with golden cords. Outside, there is a blurred view of greenery and sunlight filtering through the glass. The overall style is romantic and classical, evoking an old-world charm. The lighting is soft and natural,
highlighting her delicate features and the rich color of the violin. The woman appears serene and focused, embodying a sense of grace and musical dedication. The image conveys a peaceful, intimate atmosphere with its warm, gentle colors and elegant composition.
It's 11:07pm. Been working today on making headway of Dad's autobiography, and didn't start ComfyUI until after tea. Got a big day tomorrow with Eddie, so I'll make this my last render.
Cheers.
Autobiography Stalled¶
10.Oct.2025
Waiting for input from either Jess or Martin on the work done on Sept 30. Trying different approaches to photography of the pages: no obvious options present themselves. Updated links on the index page to all initial translation pages.
Done:
- Stubbed in Status / Mods / Comments template for each note
- Converted all page photos to clickable links, which will open in a new tab automatically
- Instead of an obscure, meaningless green tick, will get a consensus from all whether or not a page is ready for canon
- Have commenced moving pages where they seem to fit chronologically.
Plan:
- Going to a stationery shop to pick up a "display book" to house the original document pages.
Back Into Video¶
16.Oct.2025
I had my GH5 in 'repair': turns out the problem was a dodgy lens. My lovely 12-60mm Lumix Leica blah-blah-blah whatever is now a doorstop. These run AUD $1200.00 new. Doorstop. Can't be repaired. {sigh}
The camera itself is fine. I decided it was time to start using it properly. Shot some footage for a quick little video of me making a flat-white (coffee) on my Bezzera Magica.
On this ageing Macbook Pro (2015 vintage), I have a copy of Final Cut Pro, Apple's idea of intelligent video editing software. I still struggle with it. Apple, like Microsoft, have a very clear idea of HOW you should use software. Any software. Steve Jobs even said: "You're holding it wrong!" Like seriously, WTF? But anyway, I paid a chunk for the software at the time, and haven't used it for a while now. I need to get used to its quirky behaviour and yeah, going to make some videos.
When I recorded my little 'coffee' footage, I installed my GH5 on this industrial-strength, professional-grade fluid-head U-Beaut tripod. You need to see this thing: you could prop up a house with it. Made my GH5 feel like a pimple. Overkill. Thing is: just like with the camera, I need to get familiar with how it works. So, I'll set it up here and there and do footage of stuff. It's just not the sort of tripod for run-n-gun stuff.
Anyway, here's a little "Making Coffee" video:
Julia's "Arty-Farty" art-group meets on Wednesdays, and I'm the designated barista for morning tea. My lovely Bezzera coffee machine -- yes, a proper Italian-made expresso maker -- is more than up to the task: I can serve up to eight people at a go, all with different requests, reasonably quickly ... it's not the machine holding me back. New, these coffee machines run somewhere between AUD $3500 and $5000 ... but then, I never buy new if I can help it. This one is from a mob who sell and service Bezzera machines: I picked it up for $1600. The machine will outlast all of us, our cars, most likely even the house. It's built like a tank. And it makes brilliant mochas, capuchinos, lattes, flat whites ... haven't gotten into that whole "barista-art" thing yet, but the girls get great coffee so no-one's complaining.
By the way, the music was the 3rd sketch I wrote. There's another thing I want to spend a bit more time doing: writing music. Not enough hours in the day.
Python's Odd Behaviour¶
17.Oct.2025
Python has this odd behaviour: it generates error messages that impart exact NIL information to most users, and, I would warrant, though I can't be sure, even some developers. I've learnt not to trust Emily on things, either ... even some of her css (cascading style sheets) stuff has been a bit dodgy. Remember that old adage: garbage in, garbage out. Similar to: elect clowns, expect a circus.
I kept getting this error in one of Sharvin's workflows, in the ImageResizeKJv2 node: it kept spitting the dummy with: "start(0) + length(832) exceeds dimension size(64)". Wrote Sharvin about it: his reply was, "Thanks! I tried it with an image of the same dimensions and didn’t get that error. Would you be able to share the input image and the workflow (with the image added) from when you encountered the error? GitHub link if possible. I can test it on my side to check what’s going on. Yes! I'll be happy to see your version of the workflow!"
I tried the workflow again after a few days, and to my surprise.... no dramas. So, I thought he should know: "@CodeCraftersCorner -- Just re-downloaded and re-ran this workflow again. No dramas this time: works a treat. Might tweak it a bit and finally subgraph it ... I've been going absolutely like a house afire converting all my workflows into tidy little subgraphs, thanks to your excellent tutorial on that a few videos back. Thanks Sharvin!"
Yeah, except when I tried it with another image, it gave me the same error again.
Something about this issue rang vaguely familiar. Both images were PNGs, both were 2048*2048px ... the only difference was that one had an alpha channel, the other did not. The problem seemed to arise with images without an alpha channel, so I added one to the 'defective' image and updated Sharvin with this note on his YouTube channel:
"Just a little observation. This seems to be a case of the Python error revealing nothing to the uninitiated in Python (like me). This is a repeatable error: if I drop, say, a PNG into the load image that has no alpha channel, the ImageResizeKJv2 node spits the dummy with: 'start(0) + length(2048) exceeds dimension size (65)'. The image I loaded was 2048 x 2048px. I loaded the image in GIMP and added an alpha channel. Threw that into the LoadImage and the workflow happily chugged away processing it..."
I like to follow Sharvin because:
1. he's cool
2. he programs in Python
3. his reviews and subsequent workflows in ComfyUI are next-level
By the way, what is an alpha channel? It is a feature of a particular image format that allows 'transparency' in an image. Not all formats do: the PNG format supports alpha channels, the JPEG format (JPG) does not. However, you cannot assume that every PNG is going to have an alpha channel. Good to know.
SRPO is an incredible flavour of Flux! I have but barely scraped the epidermis - not even enough to elicit a capillary response - of Flux, let alone any of the subsequent flavours. I'm still messing with Flux Kontext, for cryin' out loud.
Creating low-ranking adaption is enormously rewarding. What is a low-ranking adaption? A LoRA is a tiny model YOU the end user builds to create a consistent character. If you wish to create a novel with illustrations where the character's looks remain the same, your image generator's ability to respect character consistency is crucial. Enter the LoRA, which works together with your base model. When you generate an image, you typically provide a prompt, like:


"A portrait of a short somber 16yo youth with long wavy messy brown hair. moimeme3 The person is wearing a fitted white cotton shirt with sleeves turned up and baggy jeans. The person is in a hairdressing salon. He is sweeping up from around the salon chairs. His hair is messy. Background is a room with pale white curtains on the windows and mirrors and roses in vases. Ultra-high detail, photorealistic rendering, sharp focus on on the fine textures on the hair, and rich environmental depth."
And you get the image of a guy in a shirt. Or, you give it this far more elaborate prompt:
"The photograph depicts a Victorian-era woman standing next to an old steam train. moimeme3 She has fair skin, light brown hair styled in a loose updo. Her dress is long-sleeved, black with intricate lace details on the bodice and sleeves, and it features multiple layers of ruffled fabric at the hem covering her shoes so they are barely visible. The dress buttons up the front and she wears black gloves that reach her upper arms. She holds an aged brown leather suitcase with metal clasps and a slightly worn appearance by the handle with her gloved hand. Her facial expression is serious and slightly contemplative. The steam train beside her has a dark metallic exterior with visible rivets and numbers "15" on the side. In the background, another car of the train is visible, painted in maroon with yellow accents. The background shows a dimly lit train station with arched ceilings and hanging lights. The walls are lined with dark wooden panels and vintage posters. The platform extends into the distance, fading into bright light at the far end. A yellow safety line is visible near the edge of the platform. Fallen leaves scatter on the ground beside her. The overall mood is gothic and melancholic, with a sense of timelessness. The photograph emphasizes textures such as the lace of her dress, the polished wood of the station, and the aged leather suitcase. The woman's expression is slightly pensive, adding to the somber atmosphere. The image combines elements of historical fashion with a modern photographic style. The overall color palette of the image includes muted blacks, browns, and grays, with subtle highlights from the golden brooch and metallic elements of the train. The photograph has a slightly dark and moody tone, emphasizing the Victorian era setting. The textures in the image are rich, particularly in the woman's dress fabric and the old leather suitcase."
And, you get the image of a Victorian lass at a train station in Victorian times.
Both of these images have one thing in common: the character generated by the LoRA. In the prompt, the LoRA is referenced with 'moimeme3'. Flux does all the rest. It's pretty amazing how well it works, to be honest.
Trip to Brissie¶
17.Oct.2025
Decided to have a day away from home. Drove to the Ormiston station, and caught the train. Fifty cents, half a dollar ... like seriously, why wouldn't you take the train? First stop in going to be 'my' coffee shop in Milton: they're the only place in Brisbane area that serve the Artisti-brand coffee. I can actually ask for the "Delicate" roast, which is the one I get at home. After that, I might go into the city and call in at Ted's Cameras, see if they have a variable neutral density filter and a hand grip.
The whole point to today is to walk! Lots!
Which, I did: I walked lots. First stop was 'my' cafe in Milton, the one that serves Artisti coffee. It was closed. As in: the coffee machine was missing. Looks like the proprietor moved out and is no longer trading. 🥺 😢 Buggah.
Next stop was Ted's Cameras for an Variable ND filter and a better camera bag. The filter was dear, but I got it anyway. No luck on the bag. Wandered all over Queen Street Mall and never found one. Finally decided it was time for a break, and called in at Room with Roses, a charming high tea venue in the heart of the Brisbane Arcade. Even got to say hi to Vicki Pitts, the owner. Finally, much refreshed, decided to call it a day in this hot and humid city.
Gardens and Qwen¶
19.Oct.2025
Finally pulled the finger out and did a bit of work on the last garden bed that needed a liner putting in. Not nearly as much fun as Qwen, to be honest. 🤨🤨🤨🤨🤨
Qwen, and How!¶
19.Oct.2025
Another day, another model. This time, it's Qwen. Just starting to explore this.
Please note: all images in this section are clickable for a larger version.
This is CRAZY good! The quality of the output has me seriously blown away. I'm just getting started but ... expressions:



She's serene, cross and happy. All I had to do was change the prompt.

Okay, how about a change in the background: summertime in an open-air market? And, the hair? A Victorian updo. Change the prompt, and you get output that is truly uncanny ... because the model actually obeys the prompt.
Qwen is unreal. It is open-source, unlike Flux. I haven't even tried it for video yet: just seeing it applied to images -- particularly the quality of the output, which is superb! -- has left me speechless.
So, what IS Qwen? The QwenAI blog 'explains' it, but yeah, I'm as undamaged by the information as the next person. However, when you scroll down that page, it claims you can restore photos. I still have some old family photos from a collection Nathalie sent me -- at least, I think it was from Nathalie. Might have been from Esther. Anyway:


Need I say more?
More Gardens¶

23.Oct.2025
It's Thursday, and it's going to be hot: 35°C. And it's humid. So, I'm doing nothing outside today except watering the garden.
LoRAs are not Happening!
Yesterday, I was trying to follow Emily's guidance on LoRA creation: we're talking hours of trying this, that and the other. So, it culminated in: my hardware simply wasn't on board with it. A 16gig VRAM graphics card is sort-of a middle-of-the-road graphics card, balancing affordability (if you can justify spending AUD $700+ for a graphics card, then it's affordable) and power. Sure, I lust after the 24gig cards, but at the moment they are at a pricepoint (~AUD $4000) that put them firmly out of my reach. Working within that framework (16gig VRAM / 64gig RAM) should be plenty for creating basic LoRAs using a few (<25) images in a dataset, I should think. Full-character dataset LoRAs? not so much.
Despite all our tweaking of FluxGym's environment -- FluxGym is the alternative to Kohya Script, for dummies like me, for creating LoRAs -- I never was able to create a LoRA using a 70-image dataset. So, I think -- and I shared this with Emily at the time -- that > 60 images for my use-case is overkill. It's about a face, that's it. The body ... well, Flux.1 or SRPO or even Qwen will probably have some decent suggestions.
The big challenge now isn't consistent characters: I think I've got that sorted. The image of the lass in the red dress with the glass of red was created using a LoRA I made last night with a 20-image dataset -- after those hours of futility following Emily's thinking that >60 images were essential for a decent LoRA -- and I think it works reasonably well.
Art In Practise


The tools we have now enable us to explore aspects of life the would have been forever denied us**.

That face of the lass with the wine, as well this lass sitting in a café in Paris, and a lot of faces on this page and elsewhere, ware created using a real-person face (mine) as a basis using various image models: SDXL and ReActor, then LoRAs in Flux.1 and finally Qwen. Retaining the character isn't trivial. It was through highly laborious, painstaking, multi-queue trials and fits and starts that I finally had a dataset I could use to develop a low-ranking adaptation. For a price, you can use online servers to accomplish this sort of thing, but there is a certain quiet sense of accomplishment to making a LoRA on your own system. Qwen finally, successfully age-regressed (and altered) the face and created a workable dataset, retaining the essence of the canonical image whilst allowing this new character to explore new, interesting, compelling experiences in the sparkly clouds and sunshine of the imagination. For me at least, this is the purpose of ART, in a way. After all, what else is art, but a reflection of the artist's view on life: wishful thinking? or an appalled exposé? ... or something else?
I remember my violin instructor, when I told her I was getting into AI-imaging, asking me with a vaguely suspicious look on her face: "what are you going to do with it?" Fair question. To be honest, I don't think she believed my answer. How was I going to admit that part of this was being able to 'live' vicariously on the other side of a screen? She would think I was ... weird.
Well, I am.
AI, and Flux/SRPO/Stable Diffusion/ComfyUI let me explore the imaginative side of life, write "What If" stories, explore other worlds, other existences. It's my practise of art.
Vous Dites Bizarre¶

23.Oct.2025
Julia and I picked up Eddie from his day-care and took him to his swimming lesson. Got some footage from all that on my GH5. I will need to edit it first, make it less boring. Funny though, no one does all that editing shit anymore. They 'film' and upload and make money.
Which makes me weird and pedantic. So be it.
Oh yes. YES!! I am definitely pedantic, with a generous side of weird. Evidence:
- I use Linux instead of Windows
- I avoid social media (FB, Insta, WhatsApp)
- As a bloke, I wish I weren't, hate the masc. aesthetics (self-cancelling phrase)
- Basically a hermit, can't do 'small talk', over-think things, 'Woke' writ large
- Re-use instead of recycle, for example, torn shade sail
- Multiple-time reuse Chux Superwipes (soak in NappySan)
- compost all waste biomass
- 'feed' vermin far away from the house in the compost towers, so they leave our house/garden alone
I do most of the housework because I want it done a specific way
- Stacking the dishwasher must be done to optimise water flow around dishes
- I dry clothing on a portable rack in my office to prevent clothing sunburn and horsefly bites
- All clothing is folded properly before it is put away, including fitted sheets (there's a technique)
- Don't even get me started on making coffee
- Don't go to bed with a dirty kitchen (YUCK!)
- Empty surfaces are best. Minimal clutter. No shit everywhere. Just EMPTY.
- HUGE on getting rid of stuff -- decluttering. Haven't loved it in a while? Get rid of it!!
And weird in other ways too. Of course.
Like, how these pages are evolving. The pages "live":
- First, in a folder on my Mac and in Linux called 'Sites'. I use Phoenix Code to edit them.
- Then, they are uploaaded onto GitHub into a repository using a GUI called GitHub Desktop.
- Finally, Cloudflare, my actual we host, sees an update to the repository and refreshes the pages,
If a page becomes too unwieldy (as with this Blog and the Garden Pages), they get splintered. Slowly, the old tightbyte pages and the 'HelpYrself' pages will all be folded into this one 'Projects' site. 'MyApps' (support for apps I have developed), devotionals (Good News Unlimited newsletters) and 'art', such as it is, will remain separate.
I guess a BIG question could be: WHY these pages? First answer: diary. Nothing more complicated than that. So, why not a diary on like FB or insta, like normal people do? Well, when you read the content of these pages, they contain content that might not be 'suitable' for all readers. Some (many? most?) might find these meanderings offensive. Tightbytes has been 'blessed' in the past by obscurity: I suspect these pages will only be viewed by the charitable, or the curious.
I'm thinking of doing a bit of video exploring -- shooting a bunch of footage with my GH5. My YouTube channel needs a bit of love. might be supplimented / enhanced by AI. AI can be a powerful tool to augment your imaginative creations, but too many use it to replace creativity. This is not new: case in point ... get on the Blender site and have a look at the images. What stands out? They're almost ALL images of futuristic, post-apocalyptic scenes.
This is where imagination runs these days. WTF? Ruin and desolation everywhere. How freakin' dreary!
By the way, Blender is now up to version 5 (in Beta, going to be released Nov 5th). I've sort-of gotten away from 3D now ... as Marc would say: "Je me suis calmé sûr la question." I suppose the same wi11 happen with AI-enhanced art too, at some stage.
Day in the City¶
25.Oct.2025
Took my camera (GH5) for a walk in Brisbane today. Not a millimeter of footage was shot.

Took the 280 bus from Christopher Street, a 10-minute walk from our house, if that. The 280 goes from Shoreline, a brand-new suburb just to the south of us and terminates on essentially a bus 'trunk line' to the city: the new Metro tri-articulating electric buses, which take you to Roma Street. Which is in the middle of nowhere, so I got off the 'Metro' at South Bank, and took the train to Central, where access to the city's amenities is a bit better. Bought a 20,000 something powerbank, had breakfast at a little café just under 'Room with Roses' -- smoked salmon on wholewheat! with capers! -- and wandered around people-watching, something I loved to do with Tamara back in the day, in Paris.
Took the Metro back to Griffith University, and then caught the 280 home. That was an hour's ride, just the bit from the U to our suburb. But hey! it's 50 cents, you can snooze in the bus -- I did -- and you arrive non-stressed and having done a bit of passive exercise. All positives!

I had taken some notes. Put them in Google Docs, which I can get to on my phone. I can do this from anywhere:
- To add: link for viewers to leave comments on Instagram or Messenger.
- Will not be implementing interactive fields bc I want to keep things simple and secure.
-
Will do notes on Google Docs.
-
To try: different hairstyles
When ideas occur, this seems a quick, easy, sound approach to jot stuff down. Anywhere.
I did try some hair-style-specific prompts. 'ataylorm' on his FluxHairStyles GitHub page suggested some prompts; Tansy on Medium suggested others. To be honest, not thrilled with the results so far. Neither SRPO or Qwen were consistently doing as I asked. I was probably asking it wrong.


I have found that sometime you have to do several 'queues' before Flux.1-Dev or SRPO try to nut out what you mean by "dark brown hair styled in a high ponytail with wisps framing her face". We'll do the ponytail but 'wisps'? Alors là, tu exagères.
Oh, and I went back to Qwen to try another base model. Again. As you do. I felt that Qwen was performing excessive plastic surgery. It had to only slightly step out of 'Uncanny Valley', not leave it altogether behind for greener pastures. FluxGym seems happiest building LoRAs using 10 images, and I had 20 from the Qwen Image Edit 2509 dataset workflow. Had plenty to chose from.
Notes on the Queue¶
Each model -- whether SDXL (which I almost never use), Flux.1-Dev, SRPO or Qwen -- each have their use-cases, strengths, weaknesses and queue-time length. The slowest at the moment is SRPO, but it also seems to produce the best images. Qwen seems to be best for image-to-image, but you have to be precise with your prompt, whereas with SRPO, being verbose (wordy) helps.

This photograph features a confident woman moimeme4 sitting at an office desk with sunlight streaming through a large window behind her, casting a warm glow over the scene. The woman "moimeme4" has dark brown hair in a stylish chin-length bob, and fair skin. She is wearing a crisp white button-up shirt that is slightly unbuttoned at the top, and a knee-length black skirt that highlights her slender legs. Her feet are crossed at the ankles, showing off her black high-heeled shoes. The desk in front of her is cluttered with stacks of papers, an open laptop computer, a pen, and a small lamp. She holds a pen in one hand while resting the other on the desk. The office chair she sits in is blue with a high back. The background includes more stacks of papers to either side of the window, adding to the sense of a busy workspace. The overall color palette features warm yellows and browns from the sunlight, contrasting with the cooler blues and blacks of her attire and office equipment. Her expression is serious and focused, suggesting she is concentrating on an important task. The photograph has a dynamic, almost dramatic quality due to the strong use of light and shadow.
Reads like exposition from a novel, doesn't it? This is what SRPO likes, expects, hungrily feeds on and produces quite compelling images as a consequence. I have to admit: this prompt is not originally something I wrote. To be honest, I struggle with describing things. I let Artificial Intelligence do that: it does a better job coming up with the words. However, editing ... happy to do that. Once I have raw material, I can tweak, rearrange, add key aspects and remove cruft and obvious mistakes.
So, SRPO got the face right, the hair half-right (not chin-length, but it is a bob), skirt right, legs ... um, you could make a case she is in process of crossing her legs, left hand wrong, right hand dodgy.
Oh well. I don't expect complete obedience to the prompt. Re-queue.

Ah, that's better. Somewhat.
So, where do I get the original prompt from? Well, for a baseline image, I get on Pinterest. Or Google ... which usually sends me to Pinterest. So, find an image with close to the right pose, background, whatever.
That picture gets loaded into my handy-dandy image-analysis workflow.
The node is called "Ollama Image Describer". Instead of creating images, it describes them. To do so, it takes a large-language model offered by Ollama to "look" at the image and describe what it is 'seeing'.
Note: A very interesting US-centric phenomena emerges. The US is prudish. For all its horrific societal proclivities -- and, one could make the argument, those proclivities are in part due to that prudishness -- the US sees itself as some sort of purity standard. Never more visible than when trying to actually USE one of Ollama's native models. Ludicrous. Backwards. Old white Christian Nationalist men promote child marriage, but quibble over an exposed knee.)
Fortunately, models exist to overcome this issue. And Ollama wisely allows side-loading of models it cannot supply itself. So, I was able to find 'aha2025 - llama-joycation-beta-one-hf-llava:Q4_K_M' which will honestly and without reservation describe the image.
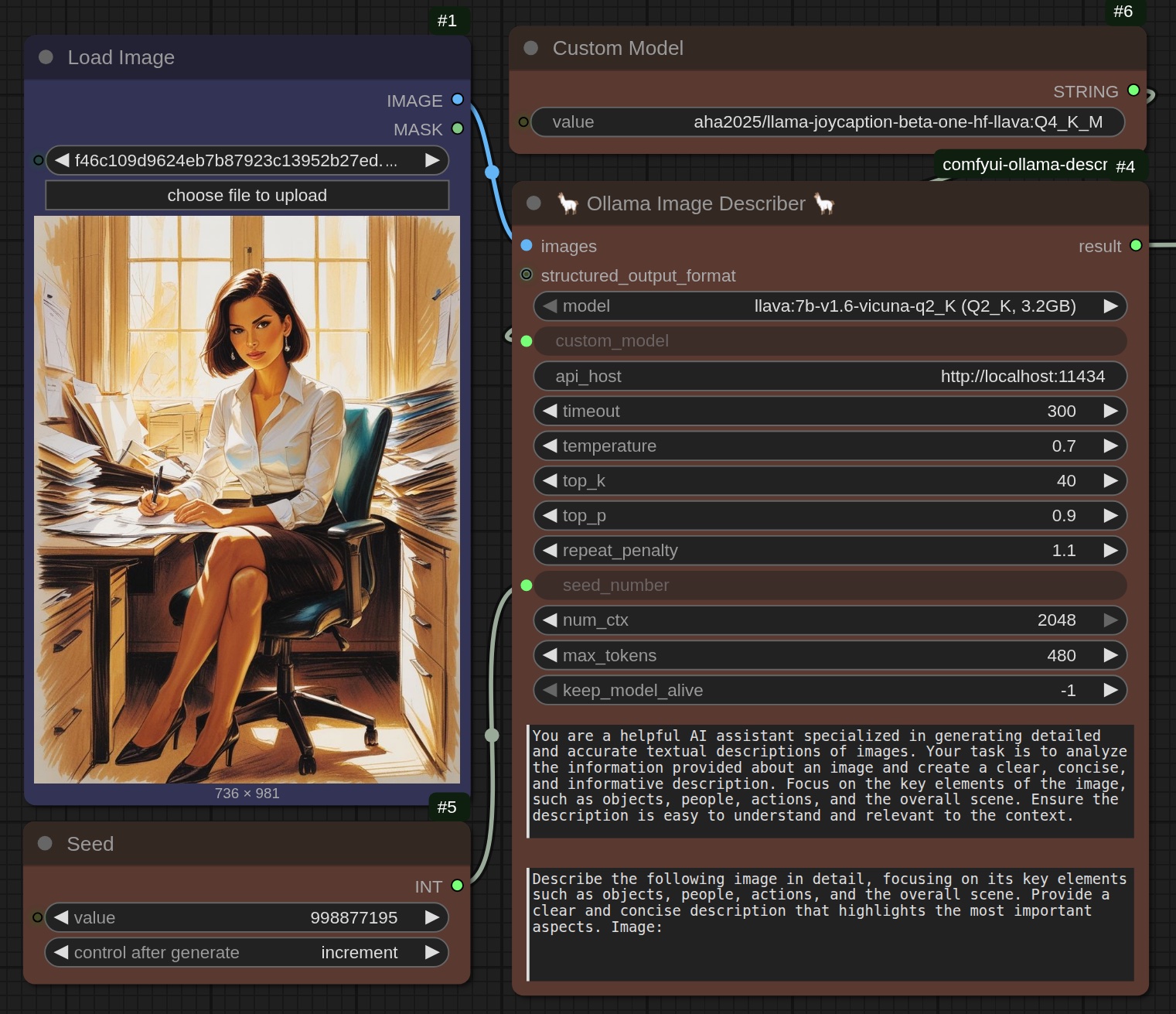
Some things to note about this process:
- The figure's pose, attire, settings: all described so SRPO understands it
- To change from drawing to realistic, all I had to say was 'photograph'
- The 'custom model' replaces the Ollama defaults, nullifying censorship
- The model itself gets instructions as to role and what to focus on
- Change to output can be done by changing the seed. Or temperature
Most importantly, you don't really need to know what top_k, top_p, num_ctx or any of that stuff is to use the node. As with most workflows you get from CivitAI, Comfy.org or your AI-imaging influencers, the defaults are usually fine. There are a few influencers I follow on YouTube and Patreon and even send a few bucks here and there, only just because their workflows are so good.
By the way, here's the original:
The image is a digital drawing done in a semi-realistic comic book style. It features a confident woman sitting at an office desk with sunlight streaming through a large window behind her, casting a warm glow over the scene. The woman has short, dark brown hair and fair skin. She is wearing a crisp white button-up shirt that is slightly unbuttoned at the top, accentuating her cleavage, and a form-fitting black skirt that highlights her slender legs. Her feet are crossed at the ankles, showing off her black high-heeled shoes. ... etc
Don't like the output? Change the seed and run it again. Running the "Ollama Image Describer" again produced:


A digital artwork featuring a confident woman seated at an office desk in a sunlit room. She has short black hair, fair skin, and is wearing a white button-down blouse with the sleeves rolled up to her elbows, and a form-fitting dark gray skirt. Her legs are crossed, showcasing her toned thighs, and she wears black high-heeled shoes. The woman holds a pen in her right hand, resting it on the desk, which is cluttered with papers, a laptop, and office supplies. She sits on a blue leather office chair with armrests, positioned slightly to the left of center. Behind her are two tall windows letting in bright sunlight, casting warm yellow and orange hues throughout the room. The walls are light-colored, contrasting with the dark furniture. The overall style is hyper-realistic with a strong use of light and shadow, emphasizing the woman's confident demeanor and professional setting. Her expression is serious yet composed, and she exudes authority and competence. The image has a slight vignette effect, drawing focus to her as the central figure.
Replace the words "A digital artwork" with "A photograph", add the LoRA keyword, and make a few other mods ... and it's happening. Made another LoRA last night to use in today's images. Happy with the results so far.
So, what is the purpose to all this?
Illustrations. Like, for picture-books. Or comic-books. Or, whatever you need illustrations for. This technique, amongst others (and there's heaps out there!) makes developing illustrations quite straightforward, reasonably accurate (just re-queue if the output isn't right) and in a style that the illustrator can decide.
At this stage I have a method for portraying one individual (one consistent character) in an image. Next is building a scene with two persons, each retaining their identity, also known as 'character consistency'. Just downloaded someone's Qwen-based workflow to achieve that end.
Another issue has made itself apparent, and there doesn't appear to be an easy fix: head size. The heads are disproportionately large, at times. Someone suggested 'PhotoPea', which is a Photoshop plugin, but I suspect you would need Photoshop to use it. Going to try Kontext (flavour of Flux.1-Dev) to see if that works. So far, it looks unlikely: it actually made it larger. Try again.
Consistent Characters¶
29.Oct.2025


Thought I'd try my hand at hairstyles.
Note: I actually had my own hair cut ... short ... I realise that in the physical world, there is going to be a growing disparity between my identity and physicality. So be it. That ship sailed ... decades ago. So, a vicarious existence is what is left me. That's fine. AI to the rescue!
I tried different hairstyles, and curly hair is surprisingly appealing. It's not a style I would have chosen, to be honest, but then, I have nil sense for that (more's the pity). I tried short bob, chignon, ponytail ... curly with ringlets works.
Who knew?
One of the issues with using LoRAs is proportions. It doesn't matter which model family -- Stable Diffusion / SDXL / Flux -- they all suffer from 'head-swelling'. Meaning: the subject's head would, after a number of 'queues' (which I'm going to go back to calling 'renders'), grow out of proportion to the rest of the body. SDXL also tended to render abnormally short people. And fingers and toes were a notorious problem for SD 1.5 and SDXL: Flux does much better.
Also did a bit of image-to-image mucking about: turning sketch-style to 'realistic'-style, with varying degrees of success.
I'll admit: I got distracted. The objective was to develop a 2-figure consistent-character workflow. So, today -- whilst not being barista for Arty-Farty -- going to get stuck into developing a 2-figure consistent-character workflow!
It WORKS!¶
2025.10.30
The two-character consistency workflow has been created. And it works!!
Well, sort-of.


It is based on this video. I had already tried several, did a search on YouTube and ran down one rabbithole after another, and they all eventually failed with errors ... until this one.
The first time I ran it, it was slow! Abysmally slow.
So slow I thought my PC had frozen, but then, it created an image.
Of course, I wasn't going to leave well-enough alone. At first I thought the slowness was due to the model: Flux.1-Dev is 23.8 gig. As in: gigabytes! Not sure what sort of magic allows a file that size to be shoe-horned into 16 gig of VRAM, but ComfyUI manages.
But it is slow. REAL slow.
(Note: turns out, the slowness was likely due to running a number of high-need workflows prior to running this one, and my poor graphics card was going: "WTF?!?")
I tried swapping Flux.1-Dev (which is a safetensor) out for a .GGUF, but failed to set stuff up correctly. GGUFs (vs .safetensors) need a different set of support nodes. And the error generated by the KSampler: 'Linear' object has no attribute 'temp'* conveyed no meaningful information to me.
But I have a friend who would know: Emily. So, I asked her. I have chronicled our Discussion for future reference.

Anyway, went with SRPO, with some interesting outcomes. Another aspect of SRPO I didn't appreciate at first is: on close-ups or mid-shots, the detail is going to be decent. But establishing shots / full-body shots leave a lot to be desired in terms of detail. Could be because I'm doing all the base work (masks and such) at a 896*896 resolution, to speed up processing. And also, perhaps, because I haven't any full-body shots of either individual in their LoRA datasets. So, there's that. As you can see: not much of either LoRA is in evidence, here. No character consistency.
Even with all of Emily's suggestions, rendering images was taking quite a while. But it was a step in the right direction! This was a major coup, one that I've been wanting to do for some time.
Consistent Chars 2¶
31.Oct.2025
So, here's the method I use to obtain these images.
First, I find an image -- on, like, Pinterest or wherever -- that depicts what I want to say. Dimensions don't matter: the final render will be square. Details do matter, but I'm not going to get too hung up on those, for now. Flux Kontext will fix those issues in post.
Next, load that image in my handy-dandy Ollama Image Describer workflow until I get close to the description (which is actually, the basis for the prompt) that I'm after. Ollama will produce something like this:
This photograph depicts two women standing side by side indoors against a backdrop of wooden shelves holding potted plants and decorative vases. Both women have light to medium skin tones and are wearing white button-up shirts with the tops partially unbuttoned, exposing their collars and some chest areas. The woman on the left has shoulder-length, straight black hair, is slightly smiling with pink lipstick, and is wearing no visible accessories. The woman on the right has long brown hair tied up in a loose bun with some strands hanging down, is smiling broadly with red lipstick, and she is pointing to her lips with her index finger while looking at the camera. The woman on the right wears a black blazer over her white shirt. Both women have minimal makeup and look approachable and professional. The background features shelves made of light-colored wood and several small plants in white pots and ornamental vases, creating a warm, welcoming atmosphere. The image has good lighting with soft shadows.
I have to point out that Ollama doesn't get it right all the time. The original image didn't have "both women ... are wearing white button-up shirts with the tops partially unbuttoned, exposing their collars and some chest areas". But oh well.
Of course, this 'description' is just the starting point. I can't use it in this state. In the workflow are two prompts, one for each character. And both prompts also have to contain some of the same information about the scene.


1st woman "moimeme3", young, slender with short brown hair styled in a retro wave, wearing a pale blue chiffon blouse over a barely visible beige lace bra. Her expression is humble, and she puts her hands behind her back.
This photograph depicts two women standing side by side indoors against a backdrop of wooden shelves holding potted plants and decorative vases. Both women have light to medium skin tones and are wearing white button-up shirts with the tops partially unbuttoned, exposing their collars and some chest areas.
... and ...
2nd woman "celestesh", tall, has shoulder-length, long brown hair tied up in a loose bun with some strands hanging down, smiling broadly and looking at the 1st woman.
This photograph depicts two women standing side by side indoors against a backdrop of wooden shelves holding potted plants and decorative vases. Both women have light to medium skin tones and are wearing white button-up shirts with the tops partially unbuttoned, exposing their collars and some chest areas.
Notice that the second part of each prompt is identical. I just copy/pasted that second part, not being too particular. I'm going to remove the reference to the open shirt and fix Celeste's hair.
And just re-render.
And again.
"Just re-render" is why I invested AUD $700+ on a GPU. That bit of kit has more than paid for itself: I have done literally thousands of queues / renders. Sure, there's Midjourney, but just creating pretty pictures of random people gets old real quick. And does Midjourney do LoRAs? No (probably due to the controversy surrounding 'deep-fakes'). Same with LeonardoAI. Of course, there are ways to run ComfyUI in the cloud. Comfy.org now have a cloud server for users with modest hardware. But those renders add up!
Anyway, I buttoned up the girls' shirts and put them in an office setting:


Last night, when I started messing with this workflow, each queue took ages (4-5 minutes) to just even begin the render process. Now, it sort-of gets a wiggle-on after 30 seconds or so. The queue itself will take up to 2 minutes, but in the grand scheme of things, I think this is a totally workable workflow.
Will I share the workflow? Why not? I think I've worked out some of the weaker aspects of the thing, as well as turned it into a nice, neat subgraph. No question there were issues, ones that weren't all that easy to resolve. It involved a better understanding of the nodes, which Emily did provide. I'm lazy ... truly, tending to simply use whatever others have created, perhaps tweaking the workflows a bit here and there, but without any sort of real understanding of how the nodes interact. Come to find out: that understanding is crucial.
Again: who knew?

Apparently Emily did. Sort-of.
At one point my characters were coming out strongly Asian. Emily gave me the right values, but for the opposite parameters. When I had the model strength at .7 and the clip strength at 1 (as she suggested), BOTH figures came out Asian. But when I swapped values (model: 1; clip: .7), neither came out even slightly Asian. The LoRA was obeyed.
Once again, AI-information proved to be inaccurate: the values for those fields were exactly opposite to what I should have entered. Buyer beware. The rest of what Emily said seemed to make sense. Will I believe it, now? Trust? But verify!
One of the advantages to having reasonably powerful hardware is privacy. I don't know how comfortable I would be testing this scene on a public server.
"À chacun son goût."


Something that Emily mentioned -- I've GOT to give her credit for that! -- and which I've experienced is that if any of the wording you use in your prompt are words used in training Asian faces (bearing in mind the SRPO model is by AliBaba, so trained in China or thereabouts) your LoRA is going to be ignored. Your figure is going to be Asian. So, changed the purple dress girl's hair colour to russet; gave the dress a square neckline.
Problem Solved.
Not sure why Celeste suddenly became so affectionate: that wasn't in the script. At least the LoRA's requirements were being respected: that's what the redhead was supposed to look like.
ComfyUI is a community as much as -- if not more than -- just an app, and one place that community is quite active is on Reddit. I thought I'd share my workflow, having given credit to the person who came up with the { mask / mask => combine-mask } idea. That's an Open-Source thing to do, I should think. In any event, within 5 hours, it had 1.4k (yep, 1400+) views and 7 likes.
No Comments. I expect comments only from those who can't get it working. 😕 🤭